
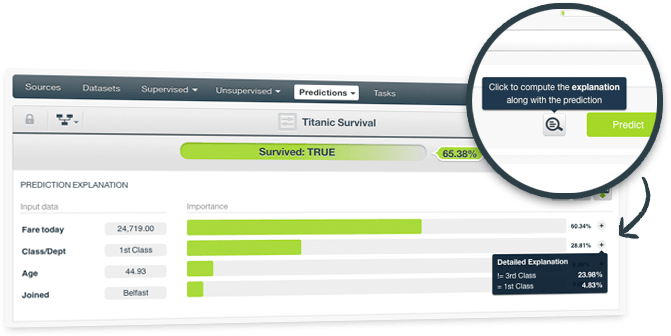
For any classification or regression model, you can now request an explanation for your predictions. The explanation represents the most important factors considered by the model in the prediction given the input values. Therefore, each input value will have an associated importance where the importances across all input values sum up to 100%.
While the prediction explanation for decision tree models is calculated using the prediction path, for other models (ensembles, logistic regression, and deepnets) the prediction explanation is calculated by aggregating the results of over a thousand distinct predictions that use random perturbations of the input data.
To read more about the prediction explanation with the BigML Dashboard please read the sections "Prediction Explanation" of the Classification and Regression document. To get the prediction explanation with the BigML API you need to use the "explain":true argument as detailed in API documentation.
As you may know, ensembles are composed of several decision trees. For non-boosted ensembles, each single tree returns a prediction given the input data. These predictions need to be combined so the ensemble returns a single prediction for each new instance.
For the previous years, BigML has been offering what we called "combiners": plurality, confidence weighted and probability weighted. Each of them provided a different strategy to combine single tree predictions. Now BigML is improving these strategies for ensembles and homogenizing the predictions across all resources, offering three new options that will replace our old combiners forever:
- Probabilities: Averages the per-class probability distributions for all trees in the ensemble and predicts the class with the highest probability. For regression ensembles, the global prediction is the mean of the individual predictions.
- Confidences: Averages the per-class confidence distributions for all trees in the ensemble and predicts the class with the highest confidence. For regression ensembles, the global prediction is the mean of the individual predictions weighted by the expected error.
- Votes: Gives one vote to each model in the ensemble. For classification models, the category with the majority of votes wins. For regression models, the global prediction is the mean of the individual predictions (it gives the same results as the probability strategy).
You can find these new options among the prediction arguments in the BigML API under the name of operating_kinds. The old combiners will also still be available from the API for a while.
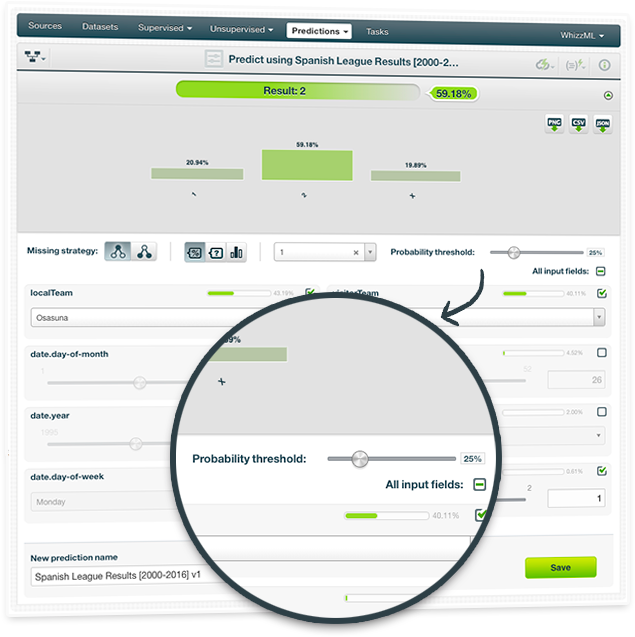
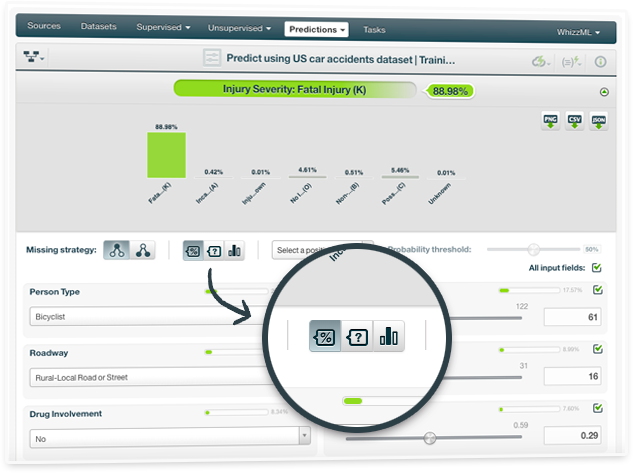
Set a threshold for the positive class when creating single predictions for any classification model. This technique is very useful for imbalanced datasets where one or a few classes are the majority classes. In these cases, models tend to predict the majority classes at the expense of the minority class that is usually the class of interest (called the positive class).
By setting a threshold for the positive class, this class will be predicted if its probability (confidence or votes depending on the type of measure you select) is greater than the established threshold, otherwise the following class with the highest probability (confidence or votes) will be predicted instead.
Whether you build a single decision tree, an ensemble, a logistic regression or a deepnet, you can select a positive class and set a threshold for a given prediction.
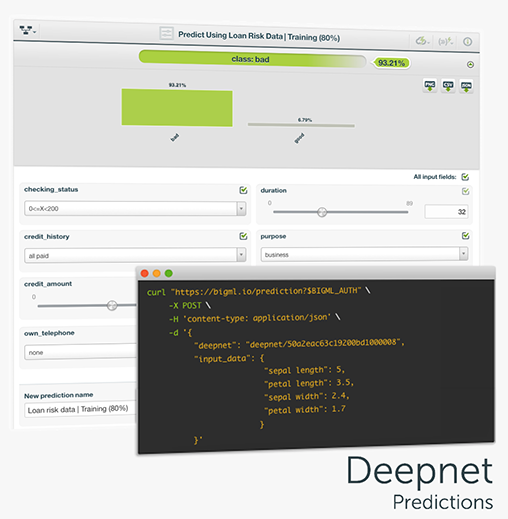
One of the main goals of any BigML resource is making predictions, and Deepnets are no exception. Deepnets can be used to predict categorical or numeric values. As Deepnets have more than one layer of nodes between the input and the output layers, the output will be the network’s prediction. In the case of categorical objective fields, an array of per-class probabilities will be returned, while a single, real value will be predicted for regression problems. You can perform single predictions, if you want to predict just one instance; or batch predictions if you want to predict multiple instances at the same time.
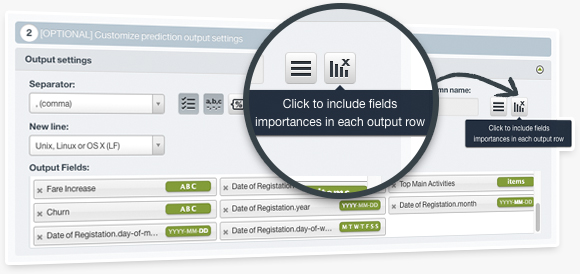
This feature enables you to include the field importances in your batch predictions, i.e., a set of percentages indicating how much each field in your dataset contributed to the prediction of a given instance. You can include those values in your output file and dataset either with BigML Dashboard or the API. This will give you a better understanding of your predictions as it will reveal which are the most relevant fields factoring in a given prediction.
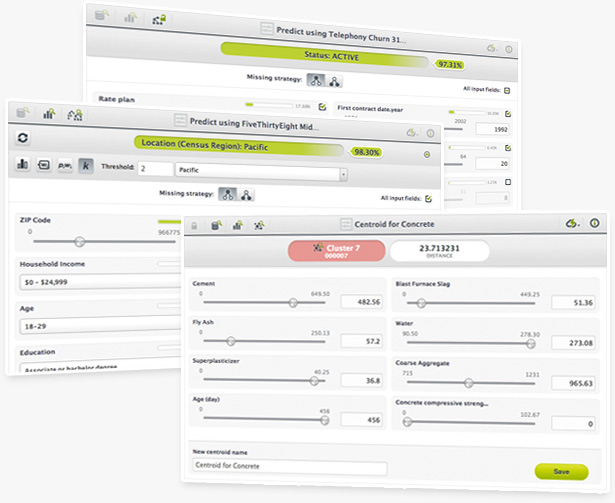
New client-side predictions make it easier than ever to explore the influence of each field in your models, ensembles or clusters. In addition, we are open sourcing the related Javascript libraries so you can leverage this functionality to build very powerful and dynamic apps and web services.
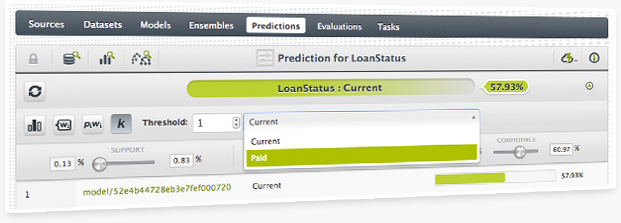
There is a new way of combining predictions from models within an ensemble called k-threshold. With this combiner you can control the trade off between the precision and recall of your predictions and tune the risks you take when making predictions.
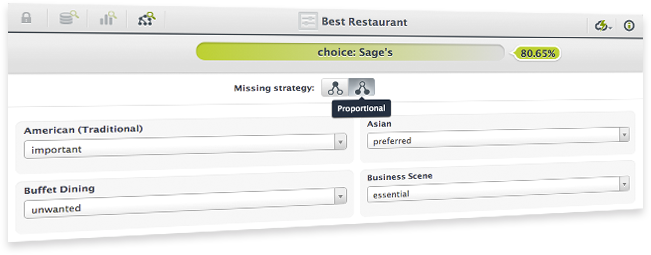
When making predictions with partial data you can now choose wether the algorithm should take into account unexplored tree branches to compute the final prediction (proportional strategy) or just stop at the given node (last prediction strategy).
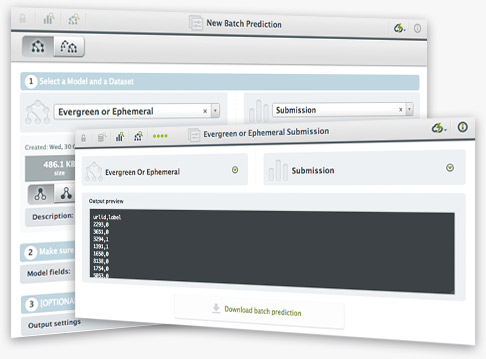
A long-awaited feature is finally here!!! BigML now allows you to create batch predictions for thousands or millions of data points without writing a single line of code. Just upload the data you want to create predictions for, transform it into a dataset and use it together with the model or ensemble to generate a downloadable file with all the predictions. You can give the file multiple formats.
There's also a new BigML.io resource that you can use to programmatically create batch predictions.