
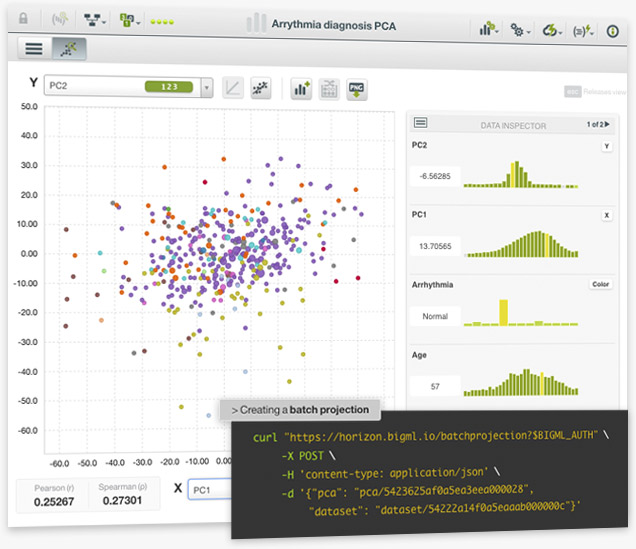
You can use your Principal Component Analysis (PCA) models to calculate the components for the same data or new data that the model has not yet seen. Predictions for PCA are referred to as projections in BigML since they can be used to project new data points to a new set of axes defined by the principal components.
When PCA is applied with the goal of dimensionality reduction, it is usually the case to set a threshold to select a subset of the principal components yielded by a PCA to transform a given dataset. You can select this subset of components in BigML either by setting a threshold for the cumulative variance explained by the components or by limiting the total number of components. The resulting dataset can be visualized in the Dashboard using the standard scatterplot. The axes can then be set to the principal components of interest, with PC1 and PC2 being the standard options to view the dimensions that display the greatest variance in the data.
Learn more about PCA on the release page.
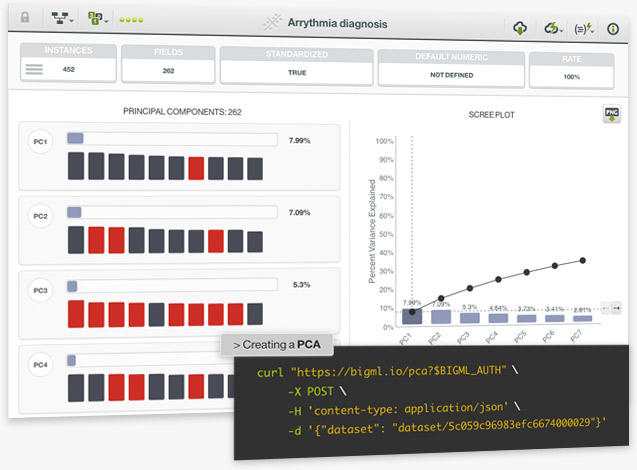
BigML is proud to announce the integration of a new unsupervised method in our platform: Principal Component Analysis (PCA). PCA is a statistical technique that transforms a dataset defined by possibly correlated variables (whose noise negatively affects the performance of your model) into a set of uncorrelated variables, called principal components. This technique is used as the first step in dimensionality reduction, especially for datasets with a large number of variables, which helps improve the performance of supervised models. BigML’s unique approach can handle numeric and non-numeric data types, including text, categorical, items fields, as well as combinations of different data types.