
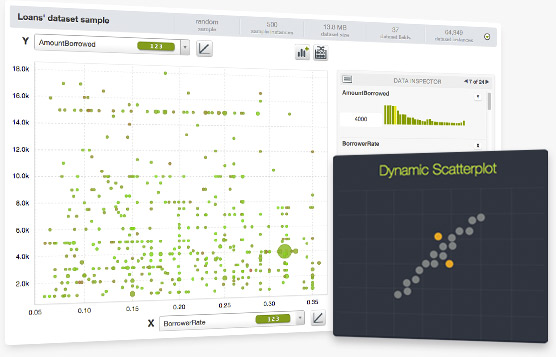
BigML's new Sample Service provides fast access to datasets that are kept in an in-memory cache which enables a variety of sampling, filtering and correlation techniques. We have leveraged this new service to create a Dynamic Scatterplot visualization that we've released into BigML Labs.
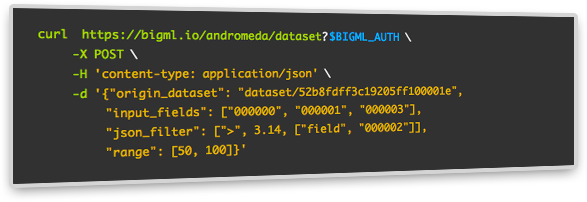
Need even more ways to transform your data? Now you can derive a new dataset by sampling, filtering, and even extending it with new fields, or concatenating it to other datasets.
In fact, you can sample, filter and extend a dataset all at once with only one API request.
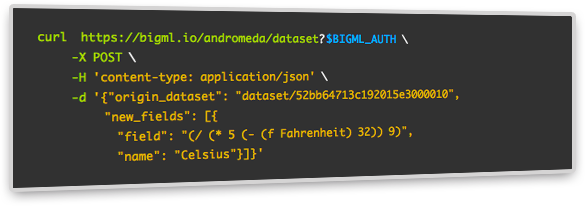
A new Lisp-like language named Flatline allows you to not only filter the rows and columns of a dataset but also generate new fields.
With Flatline you can select different fields in the same row of a dataset or select a finite sliding window of rows to traverse a dataset vertically and apply functions to them. This is useful to generate values based on a number of front and rear values.
If you prefer you can use its JSON-like variant.
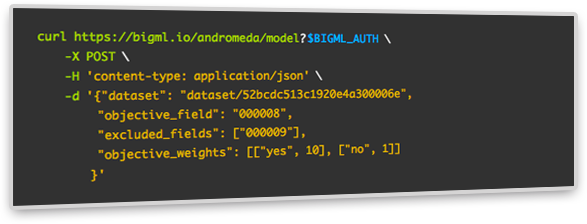
BigML’s latest release comes with three ways to elegantly cope with imbalanced datasets and create weighted models. Using them you’ll be able to build models that will consider at building time every instance or class according to the weight criteria that you establish. Read more in our developers documentation