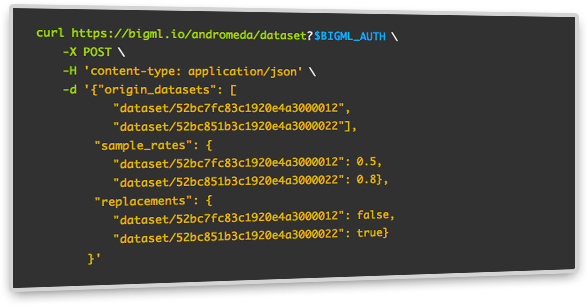
The ordering instances option in BigML allows you to sort the rows of a dataset by one or more selected fields in ascending or descending order. The instances will be sorted first by the first selected field, then by the second field, and so on. You can select up to 8 different sorting fields.
This option is very useful for time series, when you have a dataset containing a date field and you need to sort your instances chronologically.
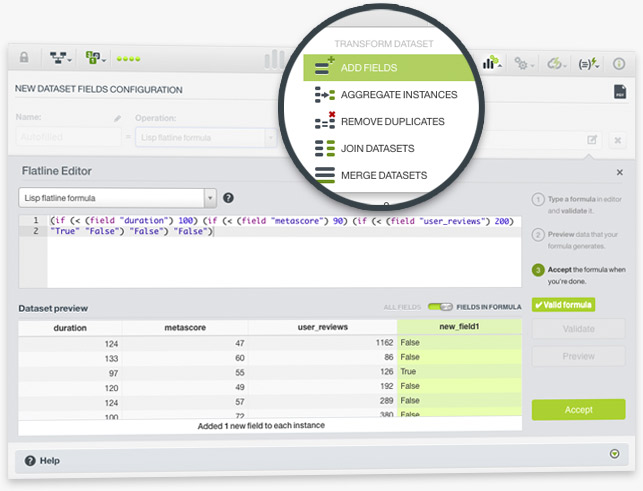
The BigML Flatline Editor has been upgraded to easily help you create new fields and validate existing Flatline expressions in your Dashboard. Flatline is BigML's domain-specific language for data generation and filtering, which helps you to perform an infinite number of calculations on top of your dataset fields.
BigML included a table-like dataset preview where you can easily see a sample of your instances. When you write a formula and you want to view its result, the preview only shows the fields involved in the formula. That way you can quickly check if your formula is being calculated correctly. Moreover, BigML also included a formula autocompletion so it's convenient to see which operators and dataset fields you can use while writing in the editor.
Find more information in the Datasets with the BigML Dashboard document.
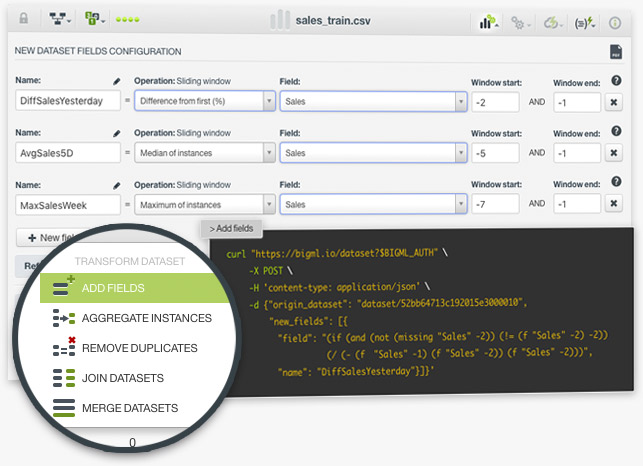
Creating new features using sliding windows is one of the most common feature engineering techniques in Machine Learning. It is usually applied to frame time series data using previous data points as new input fields to predict the next time data points. For example, imagine we have one year of sales data to predict sales, we can use our sales field to create an infinite number of fields containing past data: last day sales, the average of last week sales, the difference between last month and this month sales, etc. To set up an sliding window in BigML you just need to choose the operation you want to apply to the instances in the window and define a window start and end.
Find more information in the Datasets with the BigML Dashboard document.
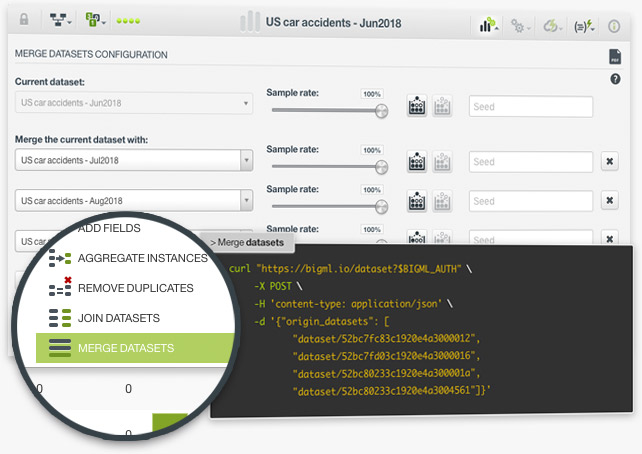
The merging datasets option in BigML allows you to include the instances of several datasets in one dataset. This functionality can be very useful when you use multiple sources of data. For example, imagine that you collect data on an hourly basis and want to create a dataset aggregating data collected over the whole day. You only need to send the new data generated each hour to BigML, create a source and a dataset for each one, and then merge all the individual datasets into one at the end of the day.
Find more information in the Datasets with the BigML Dashboard document.
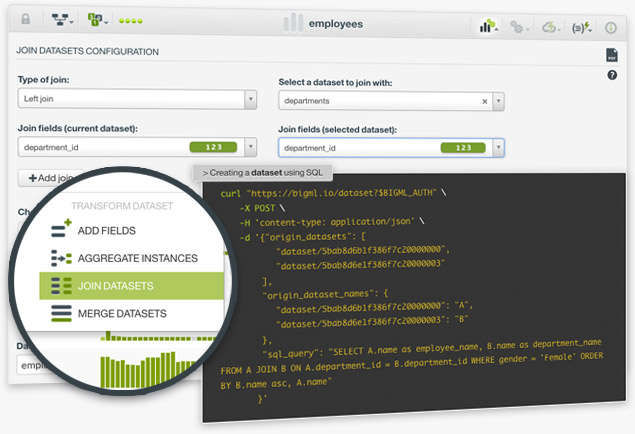
BigML allows you to join several datasets to combine their fields and instances based on one or more related fields between them. This is very useful when your data is scattered in two or more datasets. For example, imagine you have employee data in one dataset and department data in another dataset. You can add the department information per employee if you have a common field to join them such as department_id.
Find more information in the Datasets with the BigML Dashboard document.
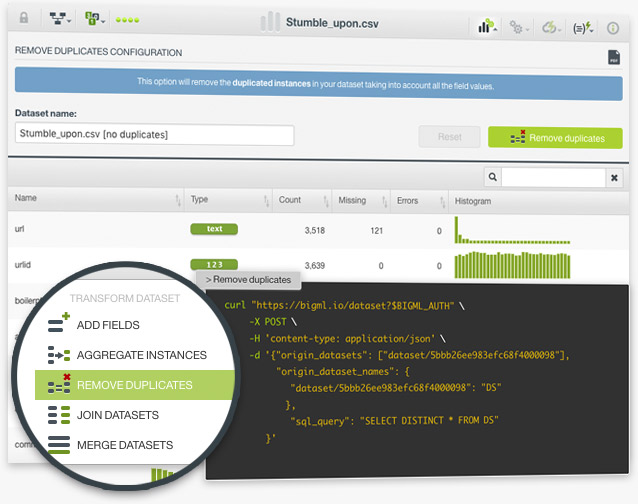
Duplicated instances in a dataset can be problematic for training Machine Learning models. For example, if you make a random split of your dataset and you take one subset for training and other for testing, it's likely that these duplicated instances appear in both subsets, which will give you an unrealistically good performance of your model. With BigML you can now easily remove the duplicated instances in your datasets with one click.
Find more information in the Datasets with the BigML Dashboard document.
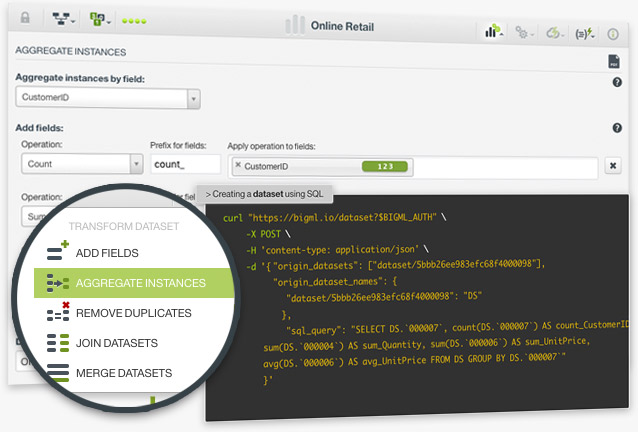
The aggregating instances option in BigML allows you to group the rows of a dataset by a given field. This is a very common case in Machine Learning. For example, imagine you have a dataset in which each instance is a purchase but you want to make an analysis based on customers, not purchases. In this case, you need to group your instances per customer to have a customer per row instead of a purchase.
In BigML, you can also perform multiple aggregation operations on top of the dataset fields such as sum, average, maximum, minimum, count, and count distinct, among others.
Find more information in the Datasets with the BigML Dashboard document.

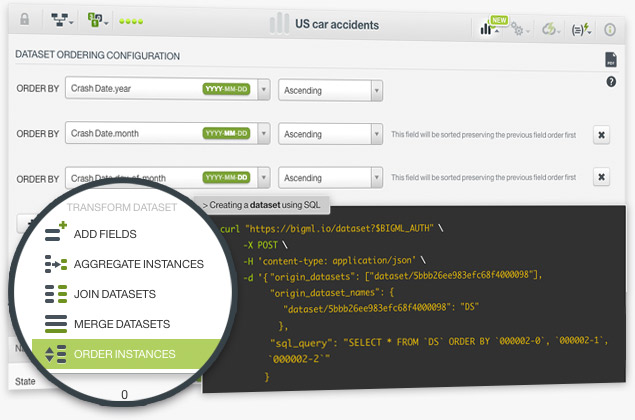
The BigML team is proud to announce SQL capabilities in the BigML API . This new feature opens up an infinite number of transformations to prepare your data for Machine Learning. The ability to freely write SQL statements will be an API-only feature for now; however, we are bringing some common transformations to the Dashboard for users that prefer to transform their data in a few clicks: aggregate instances, remove duplicates, join and merge datasets. The idea is to add more options in the Dashboard on an ongoing basis; for example, the ability to order instances.
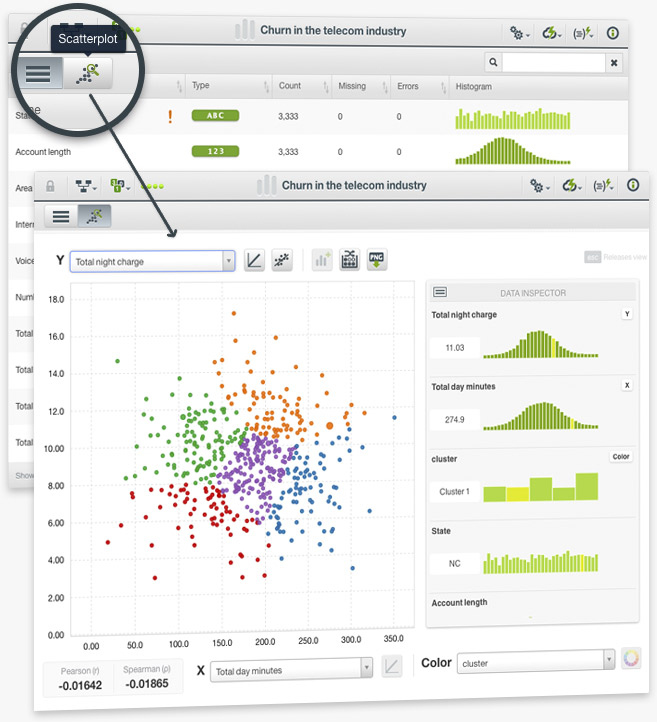
The scatterplot has been licensed from Labs (our playground environment for new experiments) to the BigML Dashboard. This visual chart allows you to look at correlations and other interesting relationships between the categorical and numeric fields in your datasets. The scatterplot is the starting point to add more visualizations for your dataset in the future such as stacked bar charts or maps for geo-data.
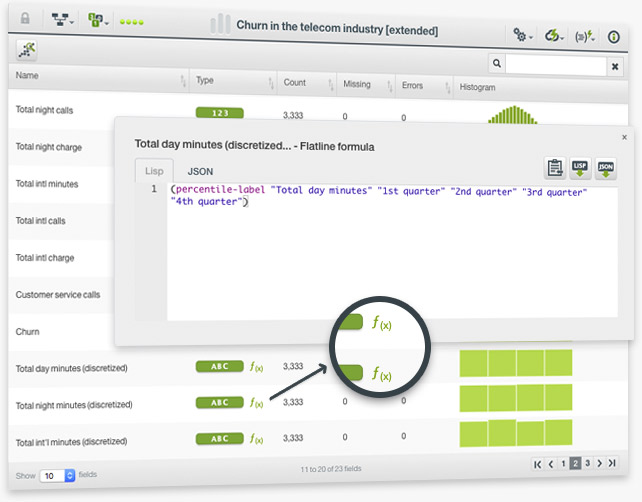
You can create new fields for your dataset if you choose the option "Add fields" from the dataset configuration menu in the Dashboard. Then you can either use our pre-defined options or the Flatline editor to create the field. Both options use BigML’s domain-specific language Flatline to generate the new fields.
Now, each time you create a new field for your dataset, you will be able to see the Flatline formula used to create it. You can easily copy and paste this formula to recreate a similar field for another dataset.
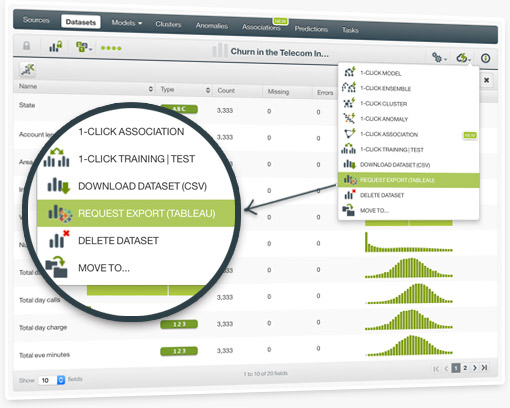
Many of you are already benefiting from the ability to incorporate and visualize your BigML models within Tableau. Now you can also export your datasets from BigML in .tde format with just 1-click. This enables you to visualize any BigML dataset (e.g., batch predictions, batch centroids, batch anomaly scores) within Tableau.
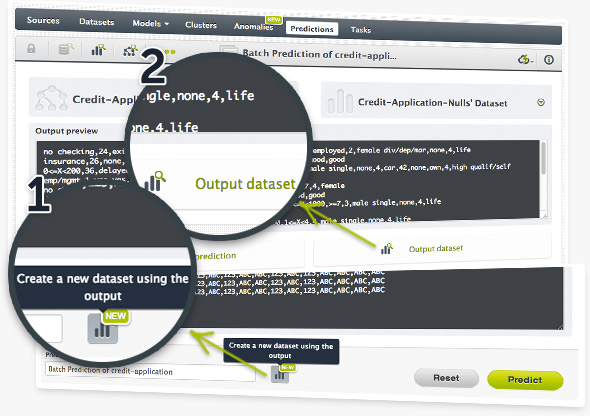
Batch predictions are a powerful way to score likely outcomes on multiple rows of data. You can now create a new dataset directly from the batch prediction output (in addition to getting the output as a .csv file).
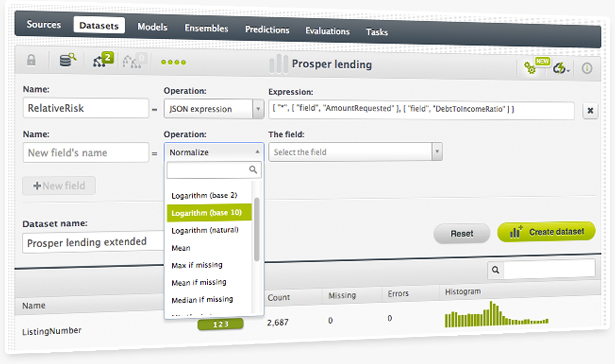
You can now add new fields to your dataset computed from existing features. There is a set of predefined generators and you can also define your own using our flatline expression language. This features is also available through the API.