Best-in-class algorithm
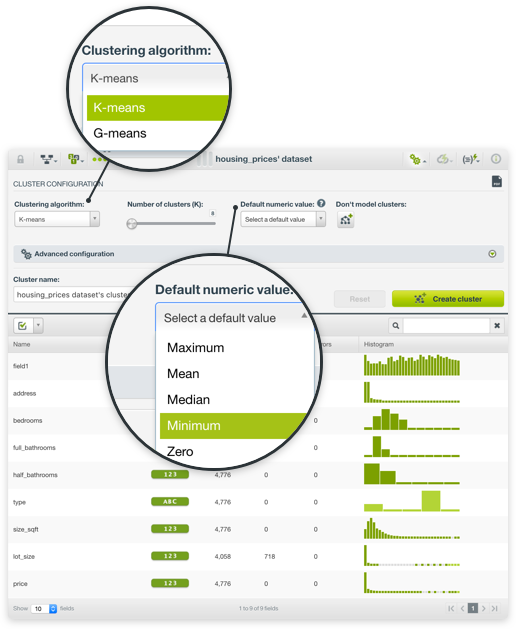
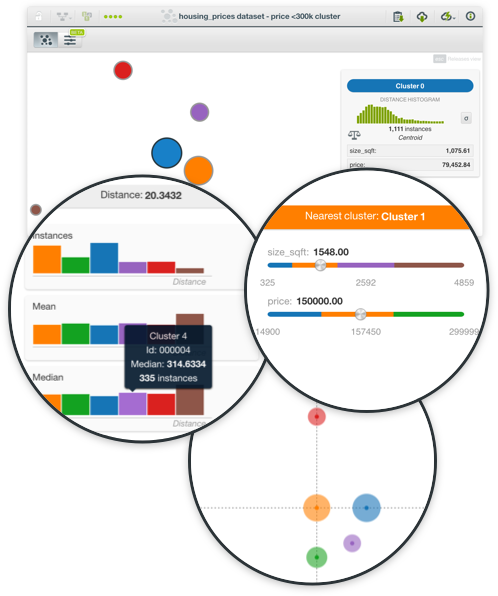
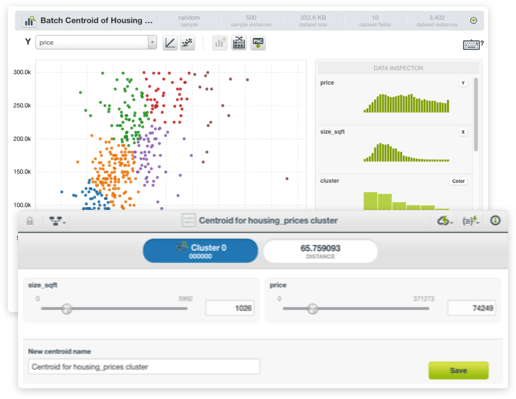
BigML clusters use optimized versions of K-means and G-means algorithms to group together the instances according to a distance measure, computed using the values of the fields as input. Each cluster group is represented by its center (or centroid). All BigML field types are valid inputs for Cluster Analyses, i.e. categorical, numeric, text and items fields, although there are a few caveats. First, numeric fields are automatically scaled to ensure that their different magnitudes do not bias the distance calculation. Second, Cluster Analysis does not tolerate missing values for numeric fields. BigML provides several strategies for dealing with them, or those instances may also be excluded entirely when computing the clusters. BigML clusters can be built using two different unsupervised learning algorithms:
- K-means: the user needs to specify the number of clusters in advance.
- G-means: the algorithm automatically learns the number of different clusters by iteratively taking existing cluster groups and testing whether the cluster's neighborhood appears Gaussian in its distribution.